


Cleaning up SPAM with NLP
Hey, it's the holidays. Time to take some PTO/Leave, hang out with family, relax, and work on some side projects. One of the many projects I finally have time for is removal of 'SPAM' messages from one of the games I play from time-to-time. This allows me to play with some NLP and solve some fun problems, like how to score a model quickly while only using a few mb of RAM in the scripting language Lua.
As someone new to Lua, and only vaguely familiar with XGBoost model dumps, there was a lot of learning to be done. However, I was able to achieve an overall accuracy rate of 95%. Not too bad for a first shot.
Introduction
Final Fantasy XI (FFXI) is a Massive Multiplayer Online Game, that I've been playing on and off for about two decades now. I primarily play the game to get in contact with old friends, enjoy the storyline, and just blow off some steam at the end of the day. However, over the last few years the primary game-wide communication system has been poluted with SPAM messages. This is problematic because, this communication system is also where people find groups to do content.
Other solutions do exist to solve this problem, but they are largely just a set of regular expressions. So I thought I would take a stab in creating a quick natural language processing (NLP) solution to see if I can do better.
One way that I can do better is to not exclusively look at two different types of messages, SPAM and not SPAM. Instead, I can look at useful classes of messages that people can decided if they want to see or not.
- Content: Content Messages.
- RMT: Real Money Trade, messages for buying/selling items using real money.
- Merc: People offering to sell content using in-game currency.
- JP Merc: People offering to 'level' your character for you.
- Chat: Consersations between players.
- Buying: Buying items using in-game currency.
- Selling: Selling items using in-game currency.
- Other: Unknown messages catch-all.
Like all problems there are constraints. Messages need to be scored in real time, on the computer running the game. To avoid maintaining a message log, messages must be considered individually, so we can't infer class by repeated message frequency as part of the scoring process.
Data Collection
I'm not going into the depths of data collection, but to do any data analysis I do need data. In particular, I need data that I can label. I utilized a project that allows for 3rd party addons for the game, windower. This framework allows a user to interact with various components of the game including in-game messaging through the programming language Lua. This allows me to write a quick plugin that records messages received from my character to a MariaDB database on my home server.
Because the addon only runs when I log into the game, it certainly is not a census of all messages, but should provide a reasonable sample of what types of messages are being sent within the game.
After running this for a few months, I was able to aquire, 98,141 messages. Unfortunately, the data does not come pre-labeled, so I manualy labeled 3,570 messages. This accounts for a total of 1,736 unique messages. For anyone interested, I've made this training data available. An sample of the first five and last five rows is provide below to provide context.
| msg | label | n | |
|---|---|---|---|
| 1 | job points 4m/500p dho gates Ž©“®‚Å‘g‚É“ü‚ê‚é | 4 | 124 |
| 2 | job points š4m/500pšš all time party dho gates autoinvite | 4 | 114 |
| 3 | job points 500p/4m 0-2100 15m dho gates moh gates igeo 4song fast tachi: jinpu 99999 | 4 | 93 |
| 4 | job points ššš "500p/4mil dho gates very fast. do you need it? all time party. buy? autoinvite. /tell | 4 | 87 |
| 5 | experience points pl do you need it? 1-99 3m 1-50 2m 50-99 2m escha - zi'tah | 4 | 70 |
| 1732 | i bet you are | 5 | 1 |
| 1733 | job points 500p do you need it? buy? dho gates fast kill | 4 | 1 |
| 1734 | kyou enmerkars earring mercenary can i have it? you can have this. 15m | 3 | 1 |
| 1735 | ea houppe. 1 ea slops 1 ninja nodowa 2 do you need it? buy? cheap bazaar@ guide stone. | 6 | 1 |
| 1736 | alexandrite 5.6k x6000 do you need it? buy? (f-8) bazaar | 6 | 1 |
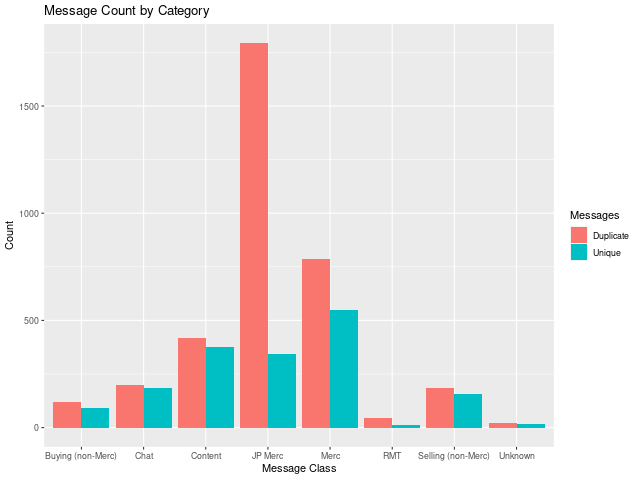
From a quick plot of overall counts of each message type, the JP Merc group clarly stands out. Although the messages in this group are rarely unique, they do account for most volume. This matches with my observations within the game. Likewise, the next largest group, Merc, also has similar trends in that there are lots of repeat messages. These two groups are commonly considered spam by most players. Content and Chat messages, the one most useful for most players are quite different from the spammy messages in both uniqueness and quantity.
Unfortunately, these observations don't help much since capturing message frequency would violate one of our requirements for message scoring. Instead, we would need to build features around model content.
Feature Building
Messages in FFXI are brief and organized. The interquartile range of unique messages within my trained data set is 46 to 78 characters. This is a bit more similar to tweets rather than a blog post or a novel. The messages within each message class are also quite similar. Content messages usually mention the activity the player is trying to do, what various jobs are needed to do this activity, and if needed the distribution of items from the activity. Likewise 'selling' messages usually describe the item, price, and a method to find or contact the individual selling the item.
Because of this brevity and organization, classifying distinct messages is fairly straight forward using n-grams and game specific terminology. The n-grams capture the distinct structure of the message, and the game specific terminology serves as a thesaurus to link together synonyms such as 'paladin', 'pld', and 'tank'. Implementation of the methods will be through a bag-of-words type approach, where each n-gram or word occurence in a message will generate a feature.
Using a little bit of tidy text it is pretty easy to build out the n-gram features to see what are the most common words and phrases. Note that common words like articles are not removed, they actually turn out to be fairly informative since they rarely show up in the spammy messages, but do show up in the 'chat' class.
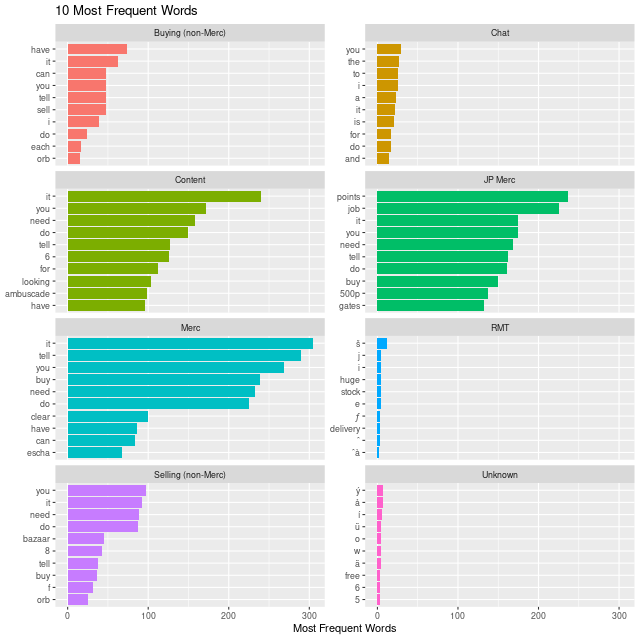
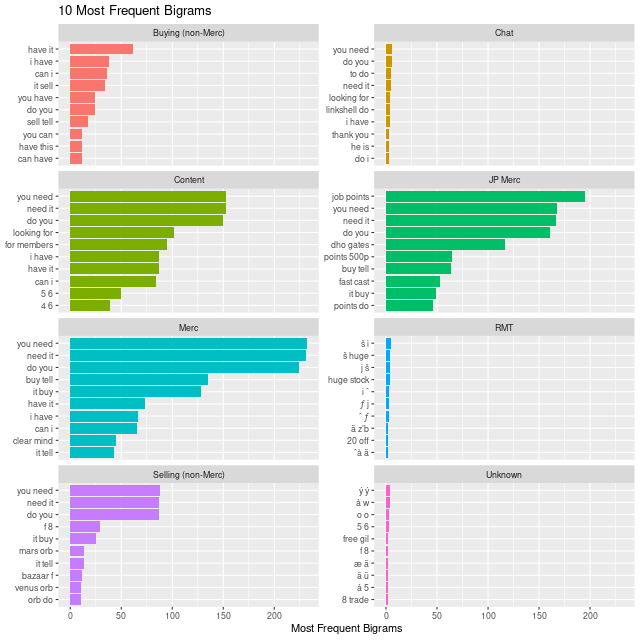
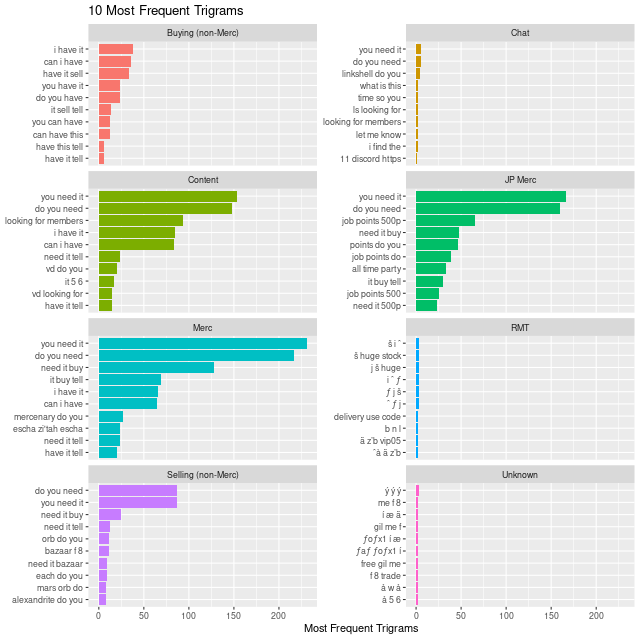
Rare words from a TF-IDF approach don't really help out here, since they either exclude important and frequent words used to separate classes, or they just identify words that would appear in the game specific terms.
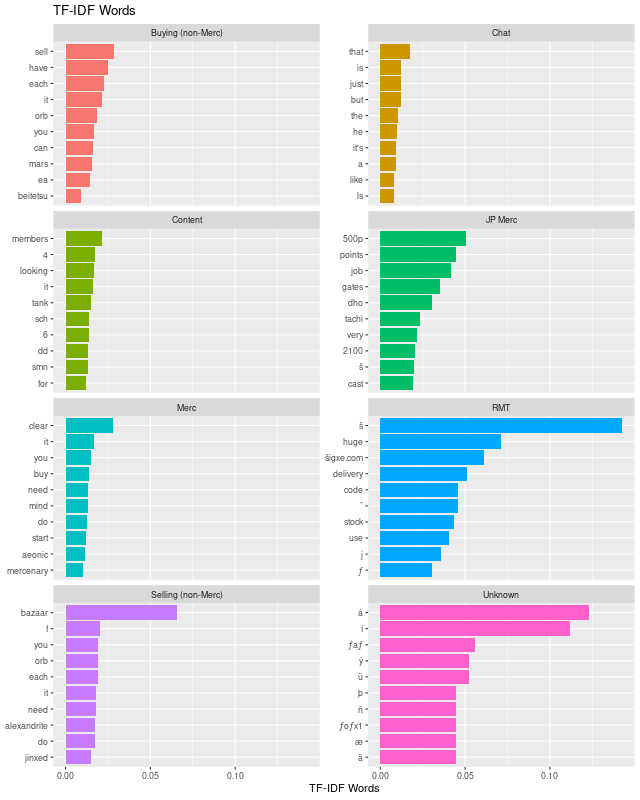
I used my own personal experience from reviewing messages and being aware of messaging mechanics to build game specific terms. These link similar game terms together which may be difficult to learn with a small data set like the one I have. To create features using these words I simply use common pattern matching strings in the form of regular expressions. These strings are portable between R and Lua, so it makes if fairly straight forward to implement in both langauges.
Note that matching isn't perfect, subsequences of words are captured along with the word. E.g. 'is' would be captured if 'this' was a part of a message. It is possible to fix this, but would require evaluation of matching implementations in R and lua. Furthermore, there are some nuances with the FFXI auto-translate function that is used frequently by users. Auto-translated words have the unfortunate consequence of having no spaces placed between words.
Model Building
Although a Neural Network approach may work better in theory, I don't have a huge amount of data. I also have a set of features that are likely to work pretty well for more traditional models, so I went with XGBoost for an initial iteration simply because it is fairly easy to interpret the results and extremely easy to score for new languages with multi-class models. This later property is due to the raw model dumps that XGBoost provides for multi-class problems.
If you are not familiar with XGBoost, it's a popular implementation of gradient boosted tree models using regularization. It allows you to fit a succession of simple models (trees), to create an ensemble of simple trees (boosting). To avoid over fitting, regularization is used to limit the impact of trees that provide little input to the model. A good overview can be found on the XGBoost site.
Implementation of an XGBoost model is fairly straight forward. We already split our data early on, so we just need to build a parameter grid; train XGBoost on our training set to find our best parameters, and then see what features we want to keep.
To train I just did a grid search with cross validation to aid in robust parameter selection. The parameters we are evaluating our model over are a reduced set from a prior and more exhaustive run. With this subset, we will still get pretty good performance and a reasonable run time, usuallly 1-2min on modern computers.
With our best parameters, we are now going to build a full model using all our training data. Based on this output, we are going to pick which features we are going to keep through a Gain threshold. Gain just gives us an idea of how important a variable is by the increase in accuracy after it is used for a split in the tree.
As an implementation note, if we were going to evaluate different gain value thresholds we would do this as part of the parameter selection step.
| Model | Log Loss |
|---|---|
| Full | 0.0663 |
| Reduced | 0.0670 |
Using our gain threshold of 0.001, we end up with 77 out of 174 variables and a minor reduction in model performance. This is a pretty good trade off and will also lower the run time for model scoring.
Model Evaluation
Now that we have our model, we want to check two important model characteristics: (1) Does the model and it's output make sense? (2) How well does the model perform?
To address the first model characteristic, models are helpful in expanding our knowledge and challenging our hypotheses. However, if they are keying in on variables in a nonsensical way, then it is usually an indication that something has gone wrong.
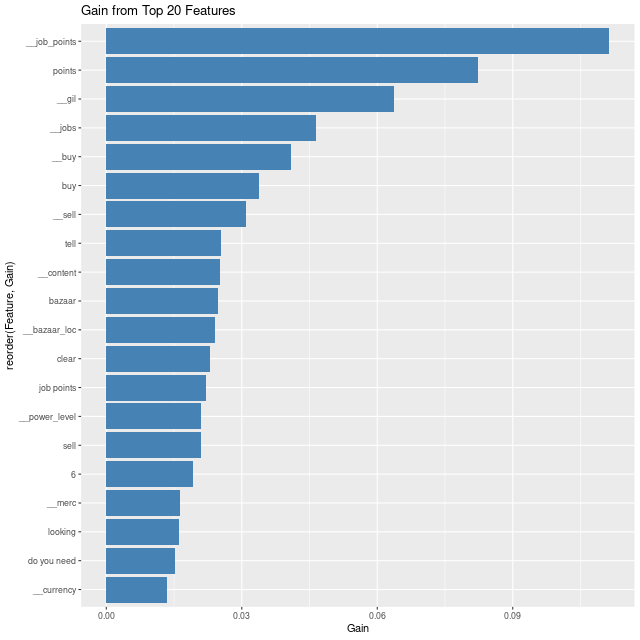
The initial way I check if a model makes sense is through feature importance. The features here should align with our understanding fo the phenomena we are modeling. If a feature is suprising, then we should do a further investigation into how that feature relates with the response.
Here the most important variables are primarily game term specific features. This ranking makes sense since variations of similar terms are captured by these features, and are present in almost all of these messages. They are also specifically created to relate to different types of content.
Specifically '__job_points' would relate primarily to people selling job points (a sort of RPG leveling system). Likewise, '__jobs' captures a large number of variations of specific jobs (think D&D classes), that would be requested in content messages.
| Model | Log Loss |
|---|---|
| Full | 89% |
| Reduced | 95% |
The second model characteristic, model performance, is evaluated through a confusion matrix, model accuracy, and per class True Positive Rates (TPR).
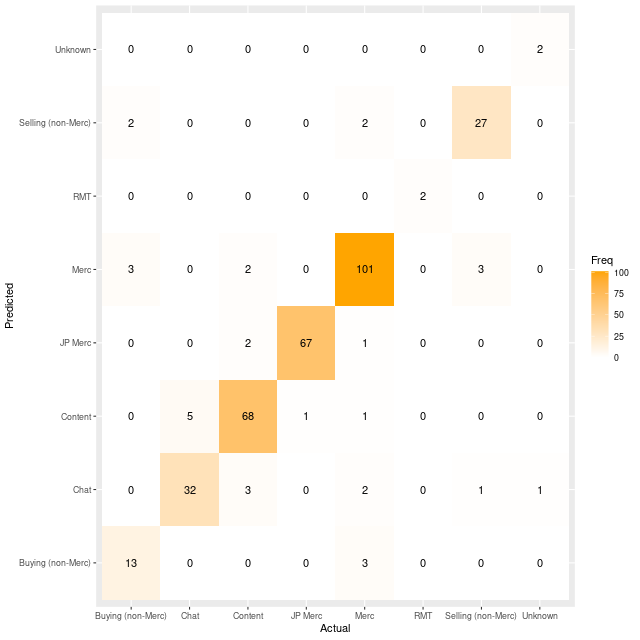
The confusion matrix shows generally good performance, where the diagonal clearly dominates the off-diagonal miss-classifications for all classes. Likewise the model accuracy is 89% for unique messages, and 95% when accounting for duplicate or repeated messages.
| Message Category | TPR | TNR | |
|---|---|---|---|
| 1 | Content | 0.91 | 0.97 |
| 2 | RMT | 1.00 | 1.00 |
| 3 | Merc | 0.89 | 0.96 |
| 4 | JP Merc | 0.99 | 0.99 |
| 5 | Chat | 0.81 | 0.98 |
| 6 | Selling (non-Merc) | 0.84 | 0.98 |
| 7 | Buying (non-Merc) | 0.67 | 0.99 |
| 8 | Unknown | 0.67 | 1.00 |
The per class TPR and FPR rates also look fairly good except for the categories 'Unknown' and 'Buying (non-Merc)'. I'm not too concerned about the 'Unknown' category since it's both fairly rare and a general catch-all of strange messages.
'Buying (non-Merc)' is a bit more of an issue. The primary separaters between 'Merc' and the '(non-Merc)' categories are the types of content or items that are being bought or sold. As an example, a Malignance Tabard is only obtained by doing specific content, it cannot directly be bought or sold buy a player. Therefore it is a merc item. But a Raetic Rod +1 can directly be bought or sold buy a player, so it would be a 'Non-Merc' item. The fix to this would be to create more game specific features to capture this, or to just to label more messages so XGBoost can identify these items on its own.
Model Deployment in Lua
To deploy the model, I need to get it out of R and into Lua. This is a five step process:
- Dump the XGBoost model to a text format
- Read in the trees from the XGBoost dump
- Wait for a new Message
- Extract features from message
- Score the message
I have already written all the code to do this in a github repo function. This also includes a previous model dump from XGBoost.
The first step is extremely easy, we just grab our model and dump it to a text file. Note that we retrain the model using all our data at this point to get the best possible fit out of all of our data.
The dump looks something like this (note this is from an earlier version of the same model):
booster[0]
0:[f11<0.5] yes=1,no=2,missing=1
1:[f194<0.5] yes=3,no=4,missing=3
3:[f211<0.5] yes=5,no=6,missing=5
5:[f215<0.5] yes=7,no=8,missing=7
7:[f64<0.5] yes=11,no=12,missing=11
11:[f197<0.5] yes=15,no=16,missing=15
15:[f76<0.5] yes=23,no=24,missing=23
23:[f210<0.5] yes=27,no=28,missing=27
27:leaf=-0.0266666692
28:leaf=-0.00392156886
24:[f210<0.5] yes=29,no=30,missing=29
29:leaf=-0.0129032256
30:leaf=-0.0380228125
16:leaf=0.11343284
12:[f129<0.5] yes=17,no=18,missing=17
17:[f195<0.5] yes=25,no=26,missing=25
25:[f201<0.5] yes=31,no=32,missing=31
31:leaf=0.0990595669
32:leaf=-0.0298507456
26:leaf=-0.037894737
18:leaf=0.259561151
8:leaf=-0.0559531562
6:[f215<0.5] yes=9,no=10,missing=9
9:[f210<0.5] yes=13,no=14,missing=13
13:[f129<0.5] yes=19,no=20,missing=19
19:leaf=0.164210528
20:leaf=-0.00784313772
14:[f129<0.5] yes=21,no=22,missing=21
21:leaf=0.189473689
22:leaf=0.323467851
10:leaf=-0.0519774035
4:leaf=-0.0562807731
2:leaf=0.366163135
...
This is in fact a single tree, given that we ran 200 iterations and there are eight categories to classify into, that gives is 1,600 trees that we need to evaluate in lua. This may seem a little daunting, but since these are trees it is fairly simple to write a recursive algorithm that will parse these structures. To do this, we should note that each line of the XGBoost dump has one of three possible line types that describe the tree structure:
- booster[m] denotes the 'm'-th tree.
- k:[f(xxx) < t] yes=h,no=i,missing=j is a branch of the tree.
- i is the index of the node within this tree.
- [f(xxx) < t] is an inequality determining if the tree will go to 'yes' f(xxx) is the feature in order of its input data set starting at 0, and t is just the value the feature is being compared against. j, k, and l are references to the node to move to given the state of the inequality for a particular row of the data set being evaluated.
- 'i:leaf=s' is a leaf node with index i and log-odd s .
In the example lua the parsing of the tree is accomplished in the read_booster function in xgboost_score.lua. It simply creates an implicit tree structure using lua arrays. Each element of the array aligns with the node index in the tree. I do add one to each index of both the features and nodes since Lua starts indexes at 0 unlike XGBoost (written in C++). Each element also contains the following components:
- feature that maps to the (xxx) part of f(xxx).
- lt_value that aligns with the value t above.
- yes_node that aligns with the value j above.
- no_node that aligns with the value k above.
- missing_node that aligns with the value l above.
- leaf the log-odds stored in the terminal node.
When a new message comes in we need to extract the features from the message to map to the features created in R. To do this we just use the regular expressions library that windower provides for lua. Here our new message is passed in as clean_text after removing non-ascii text and translating all auto-translate functions to english. As an example, this is the __gil feature we created earlier. It uses the exact same regular expression to achieve a match.
if windower.regex.match(clean_text, "[0-9]+(k|m|gil)") ~= nil then eval_features[i] = 1 end
Our next step is scoring the incomming message based on the features we just generated. As it turned out, this step was one of the harder bits of this project, not because of the technical difficulties, but in figuring out how XGBoost actually created the score.
When a new message comes in, it has it's features extracted and then we lookup in each tree for a particular message category to figure out what score it gets for each of these message categories.
The lookup step is done through a recursive function I created called eval_tree. It simply iterates over a given tree using the structure we created while reading the original tree in. As an initial condition it checks if a given node in the tree is a branch or a leaf. If we are at a leaf we are done and return our log-odds value, else we evaluate if the feature extracted from the message has a value less than our stored lt_value from our XGBoost dump. If it does, then we go to the yes_node. If the value is missing we follow the default value, equivalent to the yes_node. Otherwise, we go to the no_node. A recursive call is then made to evaluate the selected next node.
eval_tree = function( cur_node, booster, eval)
-- Is this a branch, branches have a conditional
if booster[cur_node].lt_value ~= nil then
-- this is a branch, let's check what direction to go
if( eval[ booster[cur_node].feature ] < booster[cur_node].lt_value ) then
cur_node = booster[cur_node].yes_node
elseif( eval[ booster[cur_node].feature ] == 0 ) then
cur_node = booster[cur_node].missing_node
else
cur_node = booster[cur_node].no_node
end
else
return( booster[cur_node].leaf)
end
return( eval_tree(cur_node, booster, eval) )
end
Remember that each of our 1,600 trees belong to one of eight message categories.
So for every message we get 200 values from the leaf nodes associated with a given
message category. Each of these values, which are log-odds are then summed up and
added to a default value of 0.5. This process is implemented through the
parse tree function in my Lua code.
--parse tree
eval_phrase = function( value, booster,classes )
xgboost_class = 0
score={}
for i = 1,classes do
score[i] = 0.5
end
for i = 1,table.getn(booster) do
xgboost_class = xgboost_class + 1
-- iterate over all classes
if xgboost_class > classes then
xgboost_class = 1
end
score[xgboost_class] = score[xgboost_class] + eval_tree( 1, booster[i], value)
end
-- combine score
sum_all = 0
for i = 1,classes do
sum_all = sum_all + math.exp(score[i])
end
for i = 1,classes do
score[i] = math.exp(score[i])/sum_all
end
return(score)
end
The final step is to use the softmax function to determine the probability that a given message belongs to a particular class. Here, I've just let the sum of log-odds of message category be . Finally, to end up with our probability estimate with softmax we just need to feed our sum of squares plus our prior into the softmax function:
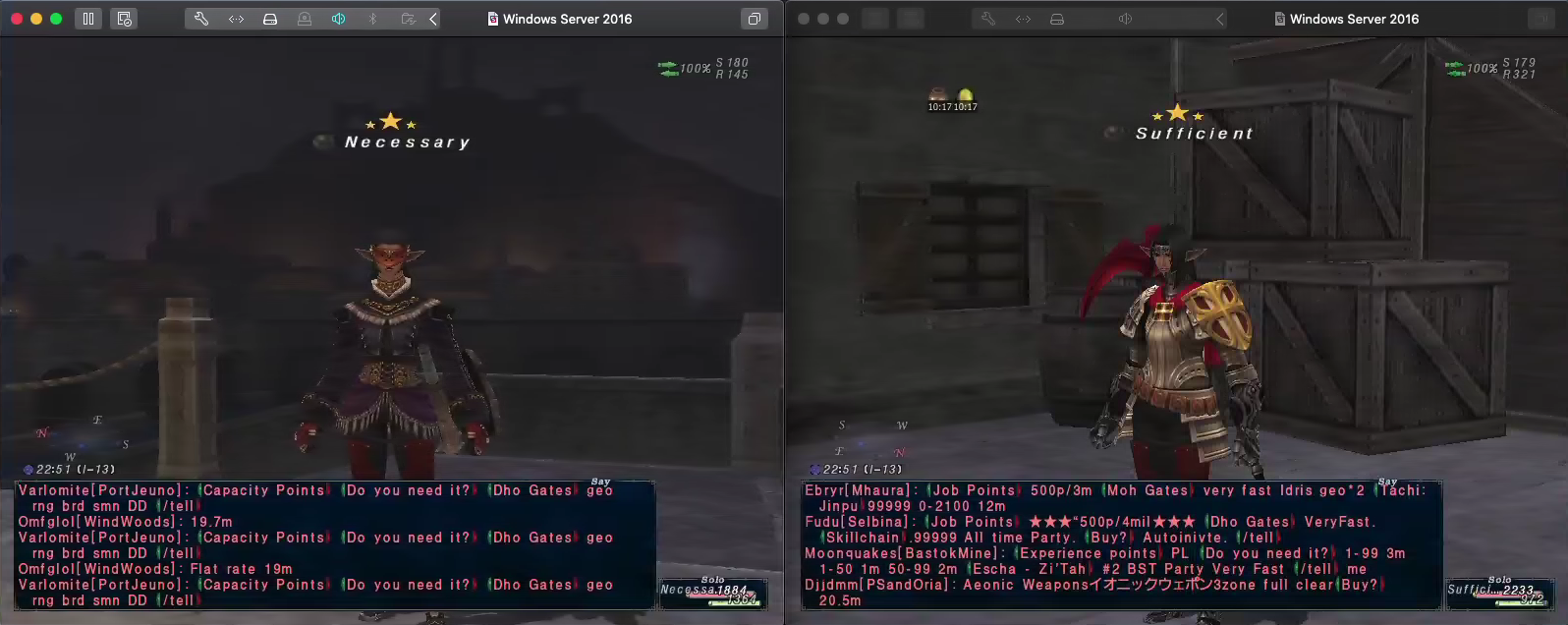
Now we have probabilities for each class of our message, and can block the message types we don't want to see. The result can be seen below where the message screen on the left is fairly free of spammy messages (Necessary), and the screen on the right has primarily spammy messages (Sufficient).
Conclusion
Through this blog post we have gone through quite a journey. We started off with a problem of message spam, used our ML insights to come up with a quick model, and produced a meaningful solution. The model attains a 95% accuracy rate for all messages, and fairly good TPR and FPR rates on a per category basis. A few more features could probably be generated to improve performance, but this serves as an excellent initial solution.
From my github stats, it looks like there have been over 200 users of this plugin, as of December 1st and hopefully more as I push out new features like automatic model updating.
Again, happy holidays and let's see your holiday ML projects!
All FFXI content and images © 2002-2020 SQUARE ENIX CO., LTD.
FINAL FANTASY is a registered trademark of SQUARE ENIX CO., LTD.